My goodness, it appears I’m writing my first Raku internals blog post in over two years. Of course, two years ago it wasn’t even called Raku. Anyway, without further ado, let’s get on with this shared brainache.
What is dispatch?
I use “dispatch” to mean a process by which we take a set of arguments and end up with some action being taken based upon them. Some familiar examples include:
- Making a method call, such as
$basket.add($product, $quantity). We might traditionally call just $product and $qauntity the arguments, but for my purposes, all of $basket, the method name 'add', $product, and $quantity` are arguments to the dispatch: they are the things we need in order to make a decision about what we’re going to do. - Making a subroutine call, such as
uc($youtube-comment). Since Raku sub calls are lexically resolved, in this case the arguments to the dispatch are &uc (the result of looking up the subroutine) and $youtube-comment. - Calling a multiple dispatch subroutine or method, where the number and types of the arguments are used in order to decide which of a set of candidates is to be invoked. This process could be seen as taking place “inside” of one of the above two dispatches, given we have both multiple dispatch subroutines and methods in Raku.
At first glance, perhaps the first two seem fairly easy and the third a bit more of a handful – which is sort of true. However, Raku has a number of other features that make dispatch rather more, well, interesting. For example:
wrap allows us to wrap any Routine (sub or method); the wrapper can then choose to defer to the original routine, either with the original arguments or with new arguments- When doing multiple dispatch, we may write a
proto routine that gets to choose when – or even if – the call to the appropriate candidate is made - We can use routines like
callsame in order to defer to the next candidate in the dispatch. But what does that mean? If we’re in a multiple dispatch, it would mean the next most applicable candidate, if any. If we’re in a method dispatch then it means a method from a base class. (The same thing is used to implement going to the next wrapper or, eventually, to the originally wrapped routine too). And these can be combined: we can wrap a multi method, meaning we can have 3 levels of things that all potentially contribute the next thing to call!
Thanks to this, dispatch – at least in Raku – is not always something we do and produce an outcome, but rather a process that we may be asked to continue with multiple times!
Finally, while the examples I’ve written above can all quite clearly be seen as examples of dispatch, a number of other common constructs in Raku can be expressed as a kind of dispatch too. Assignment is one example: the semantics of it depend on the target of the assignment and the value being assigned, and thus we need to pick the correct semantics. Coercion is another example, and return value type-checking yet another.
Why does dispatch matter?
Dispatch is everywhere in our programs, quietly tieing together the code that wants stuff done with the code that does stuff. Its ubiquity means it plays a significant role in program performance. In the best case, we can reduce the cost to zero. In the worst case, the cost of the dispatch is high enough to exceed that of the work done as a result of the dispatch.
To a first approximation, when the runtime “understands” the dispatch the performance tends to be at least somewhat decent, but when it doesn’t there’s a high chance of it being awful. Dispatches tend to involve an amount of work that can be cached, often with some cheap guards to verify the validity of the cached outcome. For example, in a method dispatch, naively we need to walk a linearization of the inheritance graph and ask each class we encounter along the way if it has a method of the specified name. Clearly, this is not going to be terribly fast if we do it on every method call. However, a particular method name on a particular type (identified precisely, without regard to subclassing) will resolve to the same method each time. Thus, we can cache the outcome of the lookup, and use it whenever the type of the invocant matches that used to produce the cached result.
Specialized vs. generalized mechanisms in language runtimes
When one starts building a runtime aimed at a particular language, and has to do it on a pretty tight budget, the most obvious way to get somewhat tolerable performance is to bake various hot-path language semantics into the runtime. This is exactly how MoarVM started out. Thus, if we look at MoarVM as it stood several years ago, we find things like:
- Some support for method caching
- A multi-dispatch cache highly tied to Raku’s multi-dispatch semantics, and only really able to help when the dispatch is all about nominal types (so using
where comes at a very high cost) - A mechanism for specifying how to find the actual code handle inside of a wrapping code object (for example, a
Sub object has a private attribute in it that holds the low-level code handle identifying the bytecode to run) - Some limited attempts to allow us to optimize correctly in the case we know that a dispatch will not be continued – which requires careful cooperation between compiler and runtime (or less diplomatically, it’s all a big hack)
These are all still there today, however are also all on the way out. What’s most telling about this list is what isn’t included. Things like:
- Private method calls, which would need a different cache – but the initial VM design limited us to one per type
- Qualified method calls (
$obj.SomeType::method-name()) - Ways to decently optimize dispatch resumption
A few years back I started to partially address this, with the introduction of a mechanism I called “specializer plugins”. But first, what is the specializer?
When MoarVM started out, it was a relatively straightforward interpreter of bytecode. It only had to be fast enough to beat the Parrot VM in order to get a decent amount of usage, which I saw as important to have before going on to implement some more interesting optimizations (back then we didn’t have the kind of pre-release automated testing infrastructure we have today, and so depended much more on feedback from early adopters). Anyway, soon after being able to run pretty much as much of the Raku language as any other backend, I started on the dynamic optimizer. It gathered type statistics as the program was interpreted, identified hot code, put it into SSA form, used the type statistics to insert guards, used those together with static properties of the bytecode to analyze and optimize, and produced specialized bytecode for the function in question. This bytecode could elide type checks and various lookups, as well as using a range of internal ops that make all kinds of assumptions, which were safe because of the program properties that were proved by the optimizer. This is called specialized bytecode because it has had a lot of its genericity – which would allow it to work correctly on all types of value that we might encounter – removed, in favor of working in a particular special case that actually occurs at runtime. (Code, especially in more dynamic languages, is generally far more generic in theory than it ever turns out to be in practice.)
This component – the specializer, known internally as “spesh” – delivered a significant further improvement in the performance of Raku programs, and with time its sophistication has grown, taking in optimizations such as inlining and escape analysis with scalar replacement. These aren’t easy things to build – but once a runtime has them, they create design possibilities that didn’t previously exist, and make decisions made in their absence look sub-optimal.
Of note, those special-cased language-specific mechanisms, baked into the runtime to get some speed in the early days, instead become something of a liability and a bottleneck. They have complex semantics, which means they are either opaque to the optimizer (so it can’t reason about them, meaning optimization is inhibited) or they need special casing in the optimizer (a liability).
So, back to specializer plugins. I reached a point where I wanted to take on the performance of things like $obj.?meth (the “call me maybe” dispatch), $obj.SomeType::meth() (dispatch qualified with a class to start looking in), and private method calls in roles (which can’t be resolved statically). At the same time, I was getting ready to implement some amount of escape analysis, but realized that it was going to be of very limited utility because assignment had also been special-cased in the VM, with a chunk of opaque C code doing the hot path stuff.
But why did we have the C code doing that hot-path stuff? Well, because it’d be too espensive to have every assignment call a VM-level function that does a bunch of checks and logic. Why is that costly? Because of function call overhead and the costs of interpretation. This was all true once upon a time. But, some years of development later:
- Inlining was implemented, and could eliminate the overhead of doing a function call
- We could compile to machine code, eliminating interpretation overhead
- We were in a position where we had type information to hand in the specializer that would let us eliminate branches in the C code, but since it was just an opaque function we called, there was no way to take this opportunity
I solved the assignment problem and the dispatch problems mentioned above with the introduction of a single new mechanism: specializer plugins. They work as follows:
- The first time we reach a given callsite in the bytecode, we run the plugin. It produces a code object to invoke, along with a set of guards (conditions that have to be met in order to use that code object result)
- The next time we reach it, we check if the guards are met, and if so, just use the result
- If not, we run the plugin again, and stack up a guard set at the callsite
- We keep statistics on how often a given guard set succeeds, and then use that in the specializer
The vast majority of cases are monomorphic, meaning that only one set of guards are produced and they always succeed thereafter. The specializer can thus compile those guards into the specialized bytecode and then assume the given target invocant is what will be invoked. (Further, duplicate guards can be eliminated, so the guards a particular plugin introduces may reduce to zero.)
Specializer plugins felt pretty great. One new mechanism solved multiple optimization headaches.
The new MoarVM dispatch mechanism is the answer to a fairly simple question: what if we get rid of all the dispatch-related special-case mechanisms in favor of something a bit like specializer plugins? The resulting mechanism would need to be a more powerful than specializer plugins. Further, I could learn from some of the shortcomings of specializer plugins. Thus, while they will go away after a relatively short lifetime, I think it’s fair to say that I would not have been in a place to design the new MoarVM dispatch mechanism without that experience.
The dispatch op and the bootstrap dispatchers
All the method caching. All the multi dispatch caching. All the specializer plugins. All the invocation protocol stuff for unwrapping the bytecode handle in a code object. It’s all going away, in favor of a single new dispatch instruction. Its name is, boringly enough, dispatch. It looks like this:
dispatch_o result, 'dispatcher-name', callsite, arg0, arg1, ..., argN
Which means:
- Use the dispatcher called
dispatcher-name - Give it the argument registers specified (the callsite referenced indicates the number of arguments)
- Put the object result of the dispatch into the register
result
(Aside: this implies a new calling convention, whereby we no longer copy the arguments into an argument buffer, but instead pass the base of the register set and a pointer into the bytecode where the register argument map is found, and then do a lookup registers[map[argument_index]] to get the value for an argument. That alone is a saving when we interpret, because we no longer need a loop around the interpreter per argument.)
Some of the arguments might be things we’d traditionally call arguments. Some are aimed at the dispatch process itself. It doesn’t really matter – but it is more optimal if we arrange to put arguments that are only for the dispatch first (for example, the method name), and those for the target of the dispatch afterwards (for example, the method parameters).
The new bootstrap mechanism provides a small number of built-in dispatchers, whose names start with “boot-“. They are:
boot-value– take the first argument and use it as the result (the identity function, except discarding any further arguments)boot-constant – take the first argument and produce it as the result, but also treat it as a constant value that will always be produced (thus meaning the optimizer could consider any pure code used to calculate the value as dead)boot-code – take the first argument, which must be a VM bytecode handle, and run that bytecode, passing the rest of the arguments as its parameters; evaluate to the return value of the bytecodeboot-syscall – treat the first argument as the name of a VM-provided built-in operation, and call it, providing the remaining arguments as its parametersboot-resume – resume the topmost ongoing dispatch
That’s pretty much it. Every dispatcher we build, to teach the runtime about some other kind of dispatch behavior, eventually terminates in one of these.
Building on the bootstrap
Teaching MoarVM about different kinds of dispatch is done using nothing less than the dispatch mechanism itself! For the most part, boot-syscall is used in order to register a dispatcher, set up the guards, and provide the result that goes with them.
Here is a minimal example, taken from the dispatcher test suite, showing how a dispatcher that provides the identity function would look:
nqp::dispatch('boot-syscall', 'dispatcher-register', 'identity', -> $capture {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-value', $capture);
});
sub identity($x) {
nqp::dispatch('identity', $x)
}
ok(identity(42) == 42, 'Can define identity dispatch (1)');
ok(identity('foo') eq 'foo', 'Can define identity dispatch (2)');
In the first statement, we call the dispatcher-register MoarVM system call, passing a name for the dispatcher along with a closure, which will be called each time we need to handle the dispatch (which I tend to refer to as the “dispatch callback”). It receives a single argument, which is a capture of arguments (not actually a Raku-level Capture, but the idea – an object containing a set of call arguments – is the same).
Every user-defined dispatcher should eventually use dispatcher-delegate in order to identify another dispatcher to pass control along to. In this case, it delegates immediately to boot-value – meaning it really is nothing except a wrapper around the boot-value built-in dispatcher.
The sub identity contains a single static occurrence of the dispatch op. Given we call the sub twice, we will encounter this op twice at runtime, but the two times are very different.
The first time is the “record” phase. The arguments are formed into a capture and the callback runs, which in turn passes it along to the boot-value dispatcher, which produces the result. This results in an extremely simple dispatch program, which says that the result should be the first argument in the capture. Since there’s no guards, this will always be a valid result.
The second time we encounter the dispatch op, it already has a dispatch program recorded there, so we are in run mode. Turning on a debugging mode in the MoarVM source, we can see the dispatch program that results looks like this:
Dispatch program (1 temporaries)
Ops:
Load argument 0 into temporary 0
Set result object value from temporary 0
That is, it reads argument 0 into a temporary location and then sets that as the result of the dispatch. Notice how there is no mention of the fact that we went through an extra layer of dispatch; those have zero cost in the resulting dispatch program.
Capture manipulation
Argument captures are immutable. Various VM syscalls exist to transform them into new argument captures with some tweak, for example dropping or inserting arguments. Here’s a further example from the test suite:
nqp::dispatch('boot-syscall', 'dispatcher-register', 'drop-first', -> $capture {
my $capture-derived := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg', $capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-value', $capture-derived);
});
ok(nqp::dispatch('drop-first', 'first', 'second') eq 'second',
'dispatcher-drop-arg works');
This drops the first argument before passing the capture on to the boot-value dispatcher – meaning that it will return the second argument. Glance back at the previous dispatch program for the identity function. Can you guess how this one will look?
Well, here it is:
Dispatch program (1 temporaries)
Ops:
Load argument 1 into temporary 0
Set result string value from temporary 0
Again, while in the record phase of such a dispatcher we really do create capture objects and make a dispatcher delegation, the resulting dispatch program is far simpler.
Here’s a slightly more involved example:
my $target := -> $x { $x + 1 }
nqp::dispatch('boot-syscall', 'dispatcher-register', 'call-on-target', -> $capture {
my $capture-derived := nqp::dispatch('boot-syscall',
'dispatcher-insert-arg-literal-obj', $capture, 0, $target);
nqp::dispatch('boot-syscall', 'dispatcher-delegate',
'boot-code-constant', $capture-derived);
});
sub cot() { nqp::dispatch('call-on-target', 49) }
ok(cot() == 50,
'dispatcher-insert-arg-literal-obj works at start of capture');
ok(cot() == 50,
'dispatcher-insert-arg-literal-obj works at start of capture after link too');
Here, we have a closure stored in a variable $target. We insert it as the first argument of the capture, and then delegate to boot-code-constant, which will invoke that code object and pass the other dispatch arguments to it. Once again, at the record phase, we really do something like:
- Create a new capture with a code object inserted at the start
- Delegate to the boot code constant dispatcher, which…
- …creates a new capture without the original argument and runs bytecode with those arguments
And the resulting dispatch program? It’s this:
Dispatch program (1 temporaries)
Ops:
Load collectable constant at index 0 into temporary 0
Skip first 0 args of incoming capture; callsite from 0
Invoke MVMCode in temporary 0
That is, load the constant bytecode handle that we’re going to invoke, set up the args (which are in this case equal to those of the incoming capture), and then invoke the bytecode with those arguments. The argument shuffling is, once again, gone. In general, whenever the arguments we do an eventual bytecode invocation with are a tail of the initial dispatch arguments, the arguments transform becomes no more than a pointer addition.
Guards
All of the dispatch programs seen so far have been unconditional: once recorded at a given callsite, they shall always be used. The big missing piece to make such a mechanism have practical utility is guards. Guards assert properties such as the type of an argument or if the argument is definite (Int:D) or not (Int:U).
Here’s a somewhat longer test case, with some explanations placed throughout it.
# A couple of classes for test purposes
my class C1 { }
my class C2 { }
# A counter used to make sure we're only invokving the dispatch callback as
# many times as we expect.
my $count := 0;
# A type-name dispatcher that maps a type into a constant string value that
# is its name. This isn't terribly useful, but it is a decent small example.
nqp::dispatch('boot-syscall', 'dispatcher-register', 'type-name', -> $capture {
# Bump the counter, just for testing purposes.
$count++;
# Obtain the value of the argument from the capture (using an existing
# MoarVM op, though in the future this may go away in place of a syscall)
# and then obtain the string typename also.
my $arg-val := nqp::captureposarg($capture, 0);
my str $name := $arg-val.HOW.name($arg-val);
# This outcome is only going to be valid for a particular type. We track
# the argument (which gives us an object back that we can use to guard
# it) and then add the type guard.
my $arg := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-guard-type', $arg);
# Finally, insert the type name at the start of the capture and then
# delegate to the boot-constant dispatcher.
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-constant',
nqp::dispatch('boot-syscall', 'dispatcher-insert-arg-literal-str',
$capture, 0, $name));
});
# A use of the dispatch for the tests. Put into a sub so there's a single
# static dispatch op, which all dispatch programs will hang off.
sub type-name($obj) {
nqp::dispatch('type-name', $obj)
}
# Check with the first type, making sure the guard matches when it should
# (although this test would pass if the guard were ignored too).
ok(type-name(C1) eq 'C1', 'Dispatcher setting guard works');
ok($count == 1, 'Dispatch callback ran once');
ok(type-name(C1) eq 'C1', 'Can use it another time with the same type');
ok($count == 1, 'Dispatch callback was not run again');
# Test it with a second type, both record and run modes. This ensures the
# guard really is being checked.
ok(type-name(C2) eq 'C2', 'Can handle polymorphic sites when guard fails');
ok($count == 2, 'Dispatch callback ran a second time for new type');
ok(type-name(C2) eq 'C2', 'Second call with new type works');
# Check that we can use it with the original type too, and it has stacked
# the dispatch programs up at the same callsite.
ok(type-name(C1) eq 'C1', 'Call with original type still works');
ok($count == 2, 'Dispatch callback only ran a total of 2 times');
This time two dispatch programs get produced, one for C1:
Dispatch program (1 temporaries)
Ops:
Guard arg 0 (type=C1)
Load collectable constant at index 1 into temporary 0
Set result string value from temporary 0
And another for C2:
Dispatch program (1 temporaries)
Ops:
Guard arg 0 (type=C2)
Load collectable constant at index 1 into temporary 0
Set result string value from temporary 0
Once again, no leftovers from capture manipulation, tracking, or dispatcher delegation; the dispatch program does a type guard against an argument, then produces the result string. The whole call to $arg-val.HOW.name($arg-val) is elided, the dispatcher we wrote encoding the knowledge – in a way that the VM can understand – that a type’s name can be considered immutable.
This example is a bit contrived, but now consider that we instead look up a method and guard on the invocant type: that’s a method cache! Guard the types of more of the arguments, and we have a multi cache! Do both, and we have a multi-method cache.
The latter is interesting in so far as both the method dispatch and the multi dispatch want to guard on the invocant. In fact, in MoarVM today there will be two such type tests until we get to the point where the specializer does its work and eliminates these duplicated guards. However, the new dispatcher does not treat the dispatcher-guard-type as a kind of imperative operation that writes a guard into the resultant dispatch program. Instead, it declares that the argument in question must be guarded. If some other dispatcher already did that, it’s idempotent. The guards are emitted once all dispatch programs we delegate through, on the path to a final outcome, have had their say.
Fun aside: those being especially attentive will have noticed that the dispatch mechanism is used as part of implementing new dispatchers too, and indeed, this ultimately will mean that the specializer can specialize the dispatchers and have them JIT-compiled into something more efficient too. After all, from the perspective of MoarVM, it’s all just bytecode to run; it’s just that some of it is bytecode that tells the VM how to execute Raku programs more efficiently!
Dispatch resumption
A resumable dispatcher needs to do two things:
- Provide a resume callback as well as a dispatch one when registering the dispatcher
- In the dispatch callback, specify a capture, which will form the resume initialization state
When a resumption happens, the resume callback will be called, with any arguments for the resumption. It can also obtain the resume initialization state that was set in the dispatch callback. The resume initialization state contains the things needed in order to continue with the dispatch the first time it is resumed. We’ll take a look at how this works for method dispatch to see a concrete example. I’ll also, at this point, switch to looking at the real Rakudo dispatchers, rather than simplified test cases.
The Rakudo dispatchers take advantage of delegation, duplicate guards, and capture manipulations all having no runtime cost in the resulting dispatch program to, in my mind at least, quite nicely factor what is a somewhat involved dispatch process. There are multiple entry points to method dispatch: the normal boring $obj.meth(), the qualified $obj.Type::meth(), and the call me maybe $obj.?meth(). These have common resumption semantics – or at least, they can be made to provided we always carry a starting type in the resume initialization state, which is the type of the object that we do the method dispatch on.
Here is the entry point to dispatch for a normal method dispatch, with the boring details of reporting missing method errors stripped out.
# A standard method call of the form $obj.meth($arg); also used for the
# indirect form $obj."$name"($arg). It receives the decontainerized invocant,
# the method name, and the the args (starting with the invocant including any
# container).
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-meth-call', -> $capture {
# Try to resolve the method call using the MOP.
my $obj := nqp::captureposarg($capture, 0);
my str $name := nqp::captureposarg_s($capture, 1);
my $meth := $obj.HOW.find_method($obj, $name);
# Report an error if there is no such method.
unless nqp::isconcrete($meth) {
!!! 'Error reporting logic elided for brevity';
}
# Establish a guard on the invocant type and method name (however the name
# may well be a literal, in which case this is free).
nqp::dispatch('boot-syscall', 'dispatcher-guard-type',
nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 0));
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal',
nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $capture, 1));
# Add the resolved method and delegate to the resolved method dispatcher.
my $capture-delegate := nqp::dispatch('boot-syscall',
'dispatcher-insert-arg-literal-obj', $capture, 0, $meth);
nqp::dispatch('boot-syscall', 'dispatcher-delegate',
'raku-meth-call-resolved', $capture-delegate);
});
Now for the resolved method dispatcher, which is where the resumption is handled. First, let’s look at the normal dispatch callback (the resumption callback is included but empty; I’ll show it a little later).
# Resolved method call dispatcher. This is used to call a method, once we have
# already resolved it to a callee. Its first arg is the callee, the second and
# third are the type and name (used in deferral), and the rest are the args to
# the method.
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-meth-call-resolved',
# Initial dispatch
-> $capture {
# Save dispatch state for resumption. We don't need the method that will
# be called now, so drop it.
my $resume-capture := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg',
$capture, 0);
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-init-args', $resume-capture);
# Drop the dispatch start type and name, and delegate to multi-dispatch or
# just invoke if it's single dispatch.
my $delegate_capture := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg',
nqp::dispatch('boot-syscall', 'dispatcher-drop-arg', $capture, 1), 1);
my $method := nqp::captureposarg($delegate_capture, 0);
if nqp::istype($method, Routine) && $method.is_dispatcher {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-multi', $delegate_capture);
}
else {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-invoke', $delegate_capture);
}
},
# Resumption
-> $capture {
... 'Will be shown later';
});
There’s an arguable cheat in raku-meth-call: it doesn’t actually insert the type object of the invocant in place of the invocant. It turns out that it doesn’t really matter. Otherwise, I think the comments (which are to be found in the real implementation also) tell the story pretty well.
One important point that may not be clear – but follows a repeating theme – is that the setting of the resume initialization state is also more of a declarative rather than an imperative thing: there isn’t a runtime cost at the time of the dispatch, but rather we keep enough information around in order to be able to reconstruct the resume initialization state at the point we need it. (In fact, when we are in the run phase of a resume, we don’t even have to reconstruct it in the sense of creating a capture object.)
Now for the resumption. I’m going to present a heavily stripped down version that only deals with the callsame semantics (the full thing has to deal with such delights as lastcall and nextcallee too). The resume initialization state exists to seed the resumption process. Once we know we actually do have to deal with resumption, we can do things like calculating the full list of methods in the inheritance graph that we want to walk through. Each resumable dispatcher gets a single storage slot on the call stack that it can use for its state. It can initialize this in the first step of resumption, and then update it as we go. Or more precisely, it can set up a dispatch program that will do this when run.
A linked list turns out to be a very convenient data structure for the chain of candidates we will walk through. We can work our way through a linked list by keeping track of the current node, meaning that there need only be a single thing that mutates, which is the current state of the dispatch. The dispatch program mechanism also provides a way to read an attribute from an object, and that is enough to express traversing a linked list into the dispatch program. This also means zero allocations.
So, without further ado, here is the linked list (rather less pretty in NQP, the restricted Raku subset, than it would be in full Raku):
# A linked list is used to model the state of a dispatch that is deferring
# through a set of methods, multi candidates, or wrappers. The Exhausted class
# is used as a sentinel for the end of the chain. The current state of the
# dispatch points into the linked list at the appropriate point; the chain
# itself is immutable, and shared over (runtime) dispatches.
my class DeferralChain {
has $!code;
has $!next;
method new($code, $next) {
my $obj := nqp::create(self);
nqp::bindattr($obj, DeferralChain, '$!code', $code);
nqp::bindattr($obj, DeferralChain, '$!next', $next);
$obj
}
method code() { $!code }
method next() { $!next }
};
my class Exhausted {};
And finally, the resumption handling.
nqp::dispatch('boot-syscall', 'dispatcher-register', 'raku-meth-call-resolved',
# Initial dispatch
-> $capture {
... 'Presented earlier;
},
# Resumption. The resume init capture's first two arguments are the type
# that we initially did a method dispatch against and the method name
# respectively.
-> $capture {
# Work out the next method to call, if any. This depends on if we have
# an existing dispatch state (that is, a method deferral is already in
# progress).
my $init := nqp::dispatch('boot-syscall', 'dispatcher-get-resume-init-args');
my $state := nqp::dispatch('boot-syscall', 'dispatcher-get-resume-state');
my $next_method;
if nqp::isnull($state) {
# No state, so just starting the resumption. Guard on the
# invocant type and name.
my $track_start_type := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $init, 0);
nqp::dispatch('boot-syscall', 'dispatcher-guard-type', $track_start_type);
my $track_name := nqp::dispatch('boot-syscall', 'dispatcher-track-arg', $init, 1);
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_name);
# Also guard on there being no dispatch state.
my $track_state := nqp::dispatch('boot-syscall', 'dispatcher-track-resume-state');
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_state);
# Build up the list of methods to defer through.
my $start_type := nqp::captureposarg($init, 0);
my str $name := nqp::captureposarg_s($init, 1);
my @mro := nqp::can($start_type.HOW, 'mro_unhidden')
?? $start_type.HOW.mro_unhidden($start_type)
!! $start_type.HOW.mro($start_type);
my @methods;
for @mro {
my %mt := nqp::hllize($_.HOW.method_table($_));
if nqp::existskey(%mt, $name) {
@methods.push(%mt{$name});
}
}
# If there's nothing to defer to, we'll evaluate to Nil (just don't set
# the next method, and it happens below).
if nqp::elems(@methods) >= 2 {
# We can defer. Populate next method.
@methods.shift; # Discard the first one, which we initially called
$next_method := @methods.shift; # The immediate next one
# Build chain of further methods and set it as the state.
my $chain := Exhausted;
while @methods {
$chain := DeferralChain.new(@methods.pop, $chain);
}
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-state-literal', $chain);
}
}
elsif !nqp::istype($state, Exhausted) {
# Already working through a chain of method deferrals. Obtain
# the tracking object for the dispatch state, and guard against
# the next code object to run.
my $track_state := nqp::dispatch('boot-syscall', 'dispatcher-track-resume-state');
my $track_method := nqp::dispatch('boot-syscall', 'dispatcher-track-attr',
$track_state, DeferralChain, '$!code');
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_method);
# Update dispatch state to point to next method.
my $track_next := nqp::dispatch('boot-syscall', 'dispatcher-track-attr',
$track_state, DeferralChain, '$!next');
nqp::dispatch('boot-syscall', 'dispatcher-set-resume-state', $track_next);
# Set next method, which we shall defer to.
$next_method := $state.code;
}
else {
# Dispatch already exhausted; guard on that and fall through to returning
# Nil.
my $track_state := nqp::dispatch('boot-syscall', 'dispatcher-track-resume-state');
nqp::dispatch('boot-syscall', 'dispatcher-guard-literal', $track_state);
}
# If we found a next method...
if nqp::isconcrete($next_method) {
# Call with same (that is, original) arguments. Invoke with those.
# We drop the first two arguments (which are only there for the
# resumption), add the code object to invoke, and then leave it
# to the invoke or multi dispatcher.
my $just_args := nqp::dispatch('boot-syscall', 'dispatcher-drop-arg',
nqp::dispatch('boot-syscall', 'dispatcher-drop-arg', $init, 0),
0);
my $delegate_capture := nqp::dispatch('boot-syscall',
'dispatcher-insert-arg-literal-obj', $just_args, 0, $next_method);
if nqp::istype($next_method, Routine) && $next_method.is_dispatcher {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-multi',
$delegate_capture);
}
else {
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'raku-invoke',
$delegate_capture);
}
}
else {
# No method, so evaluate to Nil (boot-constant disregards all but
# the first argument).
nqp::dispatch('boot-syscall', 'dispatcher-delegate', 'boot-constant',
nqp::dispatch('boot-syscall', 'dispatcher-insert-arg-literal-obj',
$capture, 0, Nil));
}
});
That’s quite a bit to take in, and quite a bit of code. Remember, however, that this is only run for the record phase of a dispatch resumption. It also produces a dispatch program at the callsite of the callsame, with the usual guards and outcome. Implicit guards are created for the dispatcher that we are resuming at that point. In the most common case this will end up monomorphic or bimorphic, although situations involving nestings of multiple dispatch or method dispatch could produce a more morphic callsite.
The design I’ve picked forces resume callbacks to deal with two situations: the first resumption and the latter resumptions. This is not ideal in a couple of ways:
- It’s a bit inconvenient for those writing dispatch resume callbacks. However, it’s not like this is a particularly common activity!
- The difference results in two dispatch programs being stacked up at a callsite that might otherwise get just one
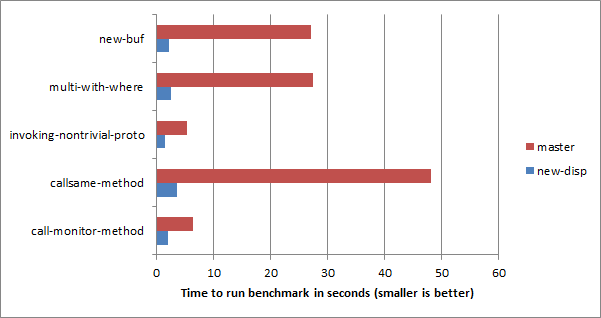
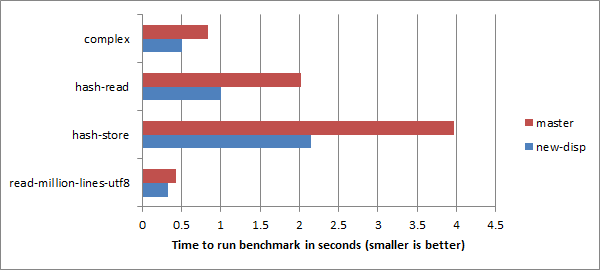
Only the second of these really matters. The reason for the non-uniformity is to make sure that the overwhelming majority of calls, which never lead to a dispatch resumption, incur no per-dispatch cost for a feature that they never end up using. If the result is a little more cost for those using the feature, so be it. In fact, early benchmarking shows callsame with wrap and method calls seems to be up to 10 times faster using the new dispatcher than in current Rakudo, and that’s before the specializer understands enough about it to improve things further!
What’s done so far
Everything I’ve discussed above is implemented, except that I may have given the impression somewhere that multiple dispatch is fully implemented using the new dispatcher, and that is not the case yet (no handling of where clauses and no dispatch resumption support).
Next steps
Getting the missing bits of multiple dispatch fully implemented is the obvious next step. The other missing semantic piece is support for callwith and nextwith, where we wish to change the arguments that are being used when moving to the next candidate. A few other minor bits aside, that in theory will get all of the Raku dispatch semantics at least supported.
Currently, all standard method calls ($obj.meth()) and other calls (foo() and $foo()) go via the existing dispatch mechanism, not the new dispatcher. Those will need to be migrated to use the new dispatcher also, and any bugs that are uncovered will need fixing. That will get things to the point where the new dispatcher is semantically ready.
After that comes performance work: making sure that the specializer is able to deal with dispatch program guards and outcomes. The goal, initially, is to get steady state performance of common calling forms to perform at least as well as in the current master branch of Rakudo. It’s already clear enough there will be some big wins for some things that to date have been glacial, but it should not come at the cost of regression on the most common kinds of dispatch, which have received plenty of optimization effort before now.
Furthermore, NQP – the restricted form of Raku that the Rakudo compiler and other bits of the runtime guts are written in – also needs to be migrated to use the new dispatcher. Only when that is done will it be possible to rip out the current method cache, multiple dispatch cache, and so forth from MoarVM.
An open question is how to deal with backends other than MoarVM. Ideally, the new dispatch mechanism will be ported to those. A decent amount of it should be possible to express in terms of the JVM’s invokedynamic (and this would all probably play quite well with a Truffle-based Raku implementation, although I’m not sure there is a current active effort in that area).
Future opportunities
While my current focus is to ship a Rakudo and MoarVM release that uses the new dispatcher mechanism, that won’t be the end of the journey. Some immediate ideas:
- Method calls on roles need to pun the role into a class, and so method lookup returns a closure that does that and replaces the invocant. That’s a lot of indirection; the new dispatcher could obtain the pun and produce a dispatch program that replaces the role type object with the punned class type object, which would make the per-call cost far lower.
- I expect both the
handles (delegation) and FALLBACK (handling missing method call) mechanisms can be made to perform better using the new dispatcher - The current implementation of
assuming – used to curry or otherwise prime arguments for a routine – is not ideal, and an implementation that takes advantage of the argument rewriting capabilities of the new dispatcher would likely perform a great deal better
Some new language features may also be possible to provide in an efficient way with the help of the new dispatch mechanism. For example, there’s currently not a reliable way to try to invoke a piece of code, just run it if the signature binds, or to do something else if it doesn’t. Instead, things like the Cro router have to first do a trial bind of the signature, and then do the invoke, which makes routing rather more costly. There’s also the long suggested idea of providing pattern matching via signatures with the when construct (for example, when * -> ($x) {}; when * -> ($x, *@tail) { }), which is pretty much the same need, just in a less dynamic setting.
In closing…
Working on the new dispatch mechanism has been a longer journey than I first expected. The resumption part of the design was especially challenging, and there’s still a few important details to attend to there. Something like four potential approaches were discarded along the way (although elements of all of them influenced what I’ve described in this post). Abstractions that hold up are really, really, hard.
I also ended up having to take a couple of months away from doing Raku work at all, felt a bit crushed during some others, and have been juggling this with the equally important RakuAST project (which will be simplified by being able to assume the presence of the new dispatcher, and also offers me a range of softer Raku hacking tasks, whereas the dispatcher work offers few easy pickings).
Given all that, I’m glad to finally be seeing the light at the end of the tunnel. The work that remains is enumerable, and the day we ship a Rakudo and MoarVM release using the new dispatcher feels a small number of months away (and I hope writing that is not tempting fate!)
The new dispatcher is probably the most significant change to MoarVM since I founded it, in so far as it sees us removing a bunch of things that have been there pretty much since the start. RakuAST will also deliver the greatest architectural change to the Rakudo compiler in a decade. Both are an opportunity to fold years of learning things the hard way into the runtime and compiler. I hope when I look back at it all in another decade’s time, I’ll at least feel I made more interesting mistakes this time around.